Recently I have been working on a microservice project for an organization with a strong culture and clear preferences on how to do things. Although this organization came from a monolithic background, we were able to achieve a satisfactory result, pleasant and constructive communication, and made some interesting design choices. I wanted to share some of the experiences to give back the community that helped us so much while deciding on the trade-offs we made. I will mostly focus on technical aspects of the microservice architecture and refrain from DDD and DevOps topics.
I will try to explain the trade-offs to the best of my ability while respecting the organization’s privacy. Without further due let’s look at the topics we will be covering;
Part 1 — (this part)
- RabbitMQ vs. Kafka
- Delayed Executions
- Distributed Tracing
- Message-Based Request/Response Structure
- WebSocket-Kafka Gateway
- Broadcasting Mechanisms
- Reusable Generic Commands
- Message Guaranties
- Automatic Retries(In-Order and Out-of-Order) with Exponential Backoffs
- Large Payload Support
- Choreography-Based Sagas
- Fault Injection
- Authorization and Authentication
- Automated Command API Generation
Before we go down the rabbit hole (a little pun intended), let me give you some background. The organization I’ve been working with was transitioning from monolithic desktop applications to web-based microservice applications. Yes, it is kind of the jump Neo made in Matrix. It is possible, but it is not going to be pain-free. Everybody falls the first time, right? Anyway, that’s what refactorings are for. Since it is already a very long jump, we didn’t want to increase the height of the target tower too, at least not too much. So we decided to limit the number of new technologies and tools to the minimum. We also decided to let some services grow a little large to cut back the number of required distributed transactions. Even with that, we are still looking at 20+ individual services (without replicas), so that’s still a lot of problems to solve.
Many of our approaches/solutions to technical problems use or dictated by another. I will be going over them in an order that helps to explain our reasoning.
RabbitMQ vs. Kafka
If you are developing an event-driven application, you are going to need a message-broker. Probably the most popular two are RabbitMQ and Kafka. In this section, I will explain why we thought one was a better fit for us than the other.
When comparing the two, I think the most helpful distinction is, RabbitMQ is a queue that pushes whereas Kafka is a log that expects consumers to pull messages. While this contrast dictates significant architectural differences, for most common scenarios, both offer similar capabilities. Many articles compare them in great detail, like this one (https://jack-vanlightly.com/blog/2017/12/4/rabbitmq-vs-kafka-part-1-messaging-topologies) so I won’t go too much into it. However, let me explain the main difference that affected our decision.
Some of our use cases require services to process specific messages in the same order they were created, so we need message ordering. And our performance goals require horizontal scaling of the services, preferably with auto-scaling.
Both frameworks handle each of these requirements separately quite well. But when you combine auto-scaling and message-ordering, Kafka comes one step ahead. Let me explain.
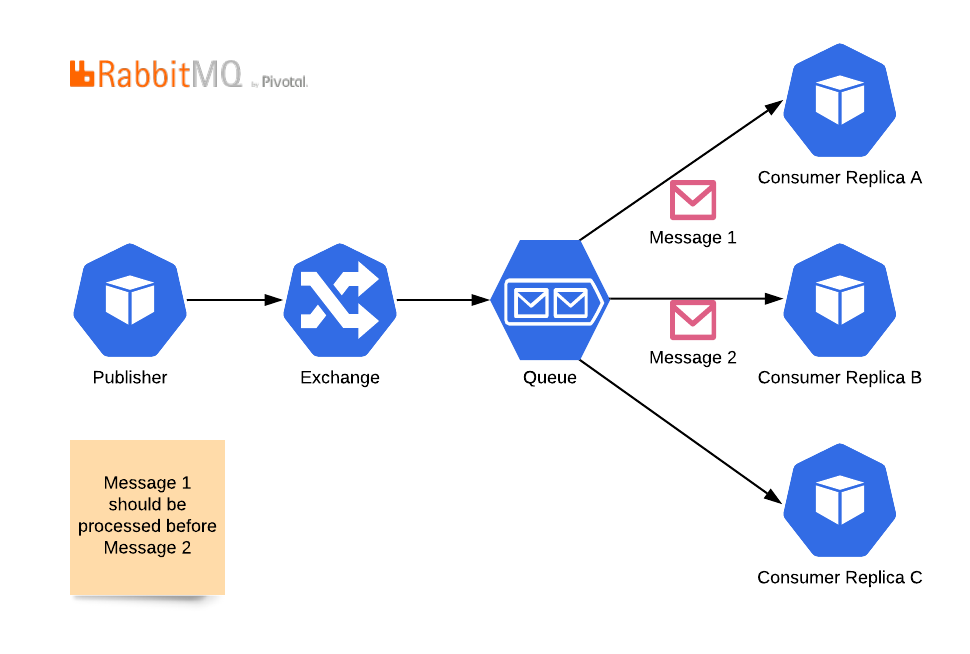
In RabbitMQ, messages go through an exchange, land on a queue then gets distributed to consumers in a way that a message can go to only one consumer. It is super easy to increase the replica count of consumers, but in this topology, you loose message ordering. Because the second message can be processed before the first one is completed. To have replicas and message ordering together you can use this topology;
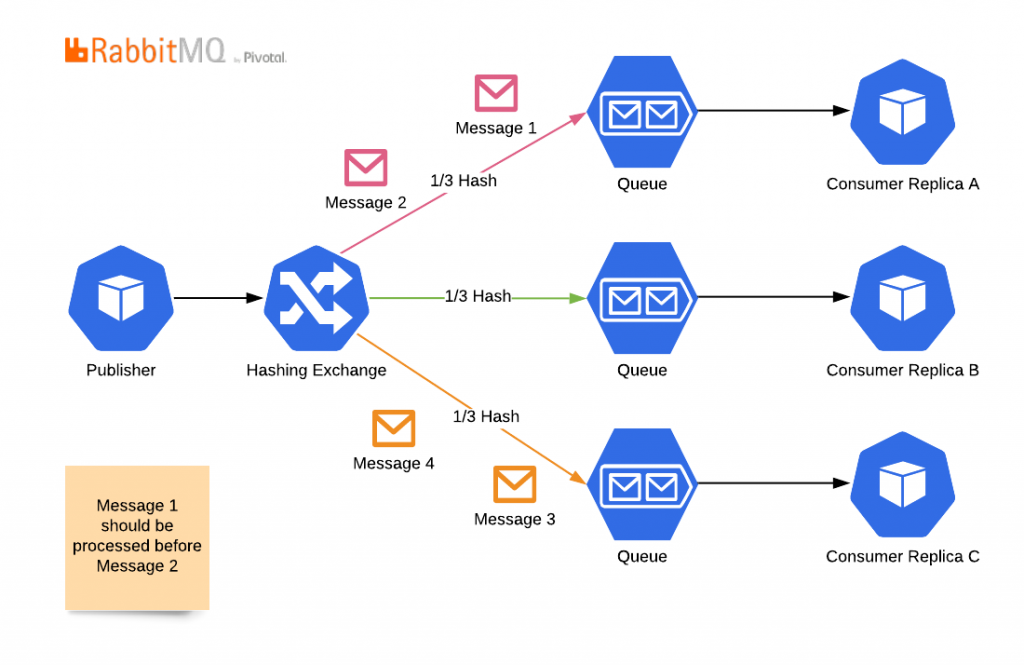
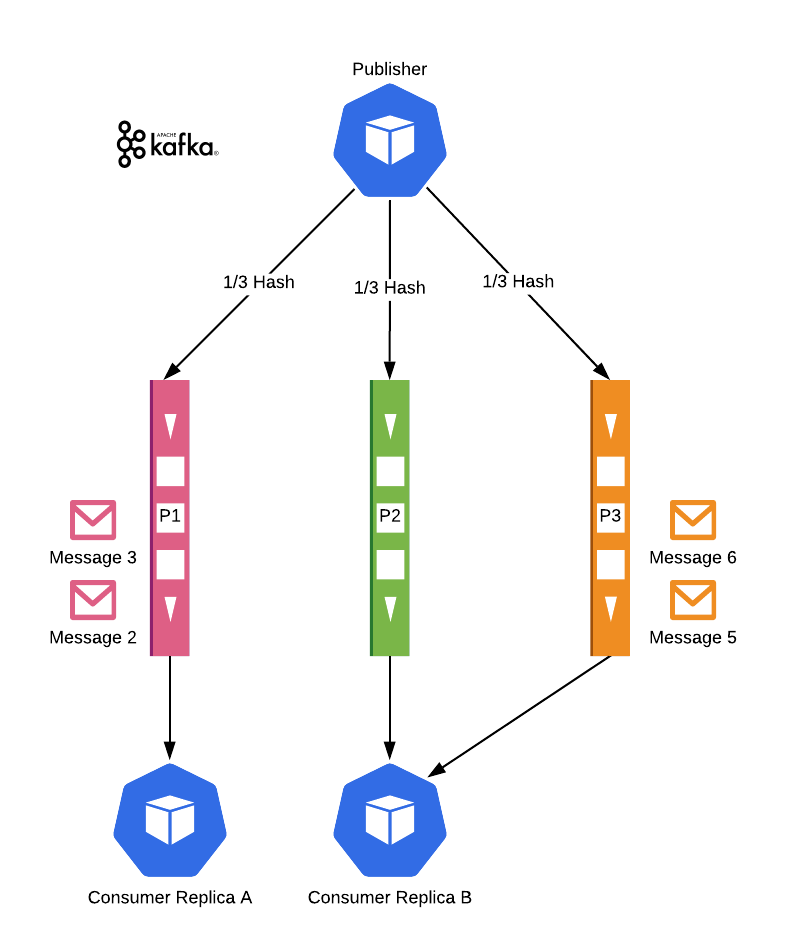
But as you can see, in this topology you loose auto-scaling. You cannot add more replicas than your hashing space allows. And even more importantly, you cannot have fewer replicas than your hashing space. Because in that case, messages go to a queue but never gets consumed.
Kısaca buradaki environment altındaki tanımlamalarımızı da özetleyecek olursak:
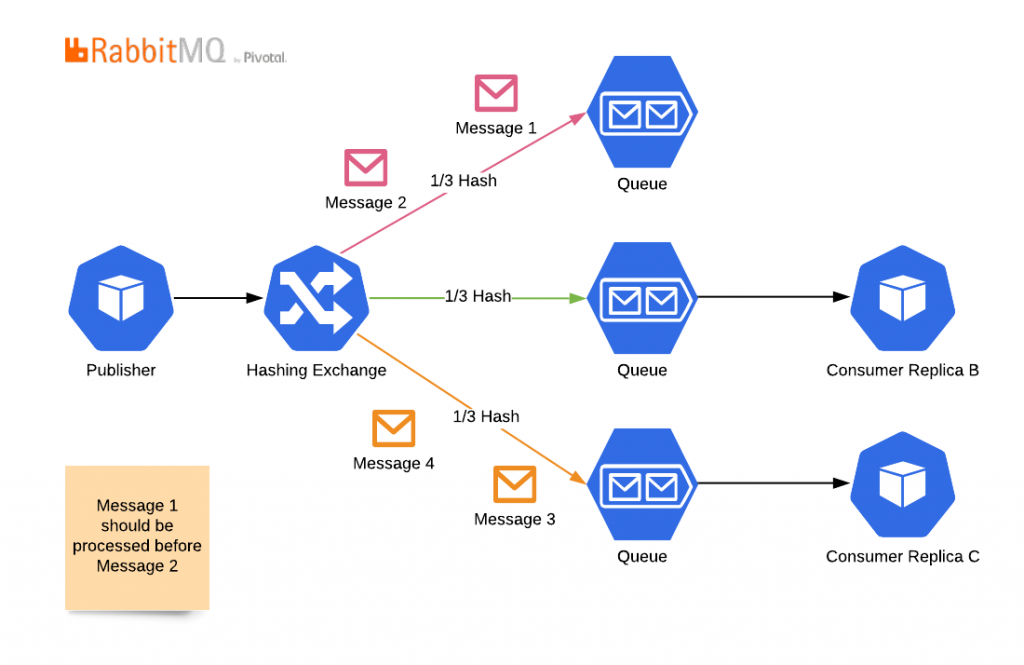
Since you will not change hashing algorithms on the fly, rearrange queues, and assign consumers, you are stuck with the number of consumers you started with. Although a consumer can subscribe to more than one queue, in practice, RabbitMQ does not provide an easy to use solution to manage these subscriptions and sync it with autoscaling algorithms.
Kafka has a different approach. It uses hashing just the same, and it has Partitions similar to the Queues we have seen with RabbitMQ. Messages have ordering guarantees in a partition but no ordering guarantees between partitions. The difference is, Kafka manages the subscriptions itself. A partition can be assigned to only one consumer (in a consumer group, think as a replica-set). If a partition has no consumers, Kafka finds one and assigns it.
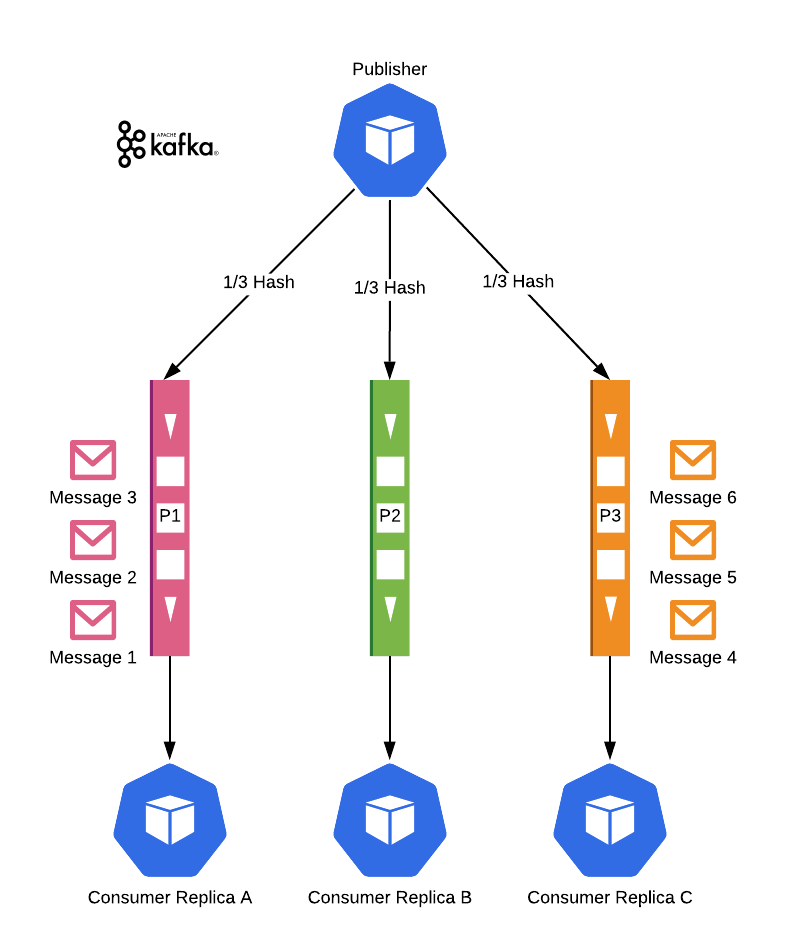
So, our hashing algorithms need to land the related messages in the same Partition. Even if auto-scaling happens in between the messages, they will be processed in order, just by different services. Therefore it is essential to keep services stateless.
Kafka has different acknowledgment mechanisms. There is auto-ack, where a message is assumed processed once it is delivered to the consumer. And there is manual-ack, where the consumer sends an acknowledgment, preferably after it processed the message. By using manual-ack, we can be sure messages are not lost and make this topology work.
Of course, the number of partitions still limits the maximum number of replicas. Excess replicas sit idle.
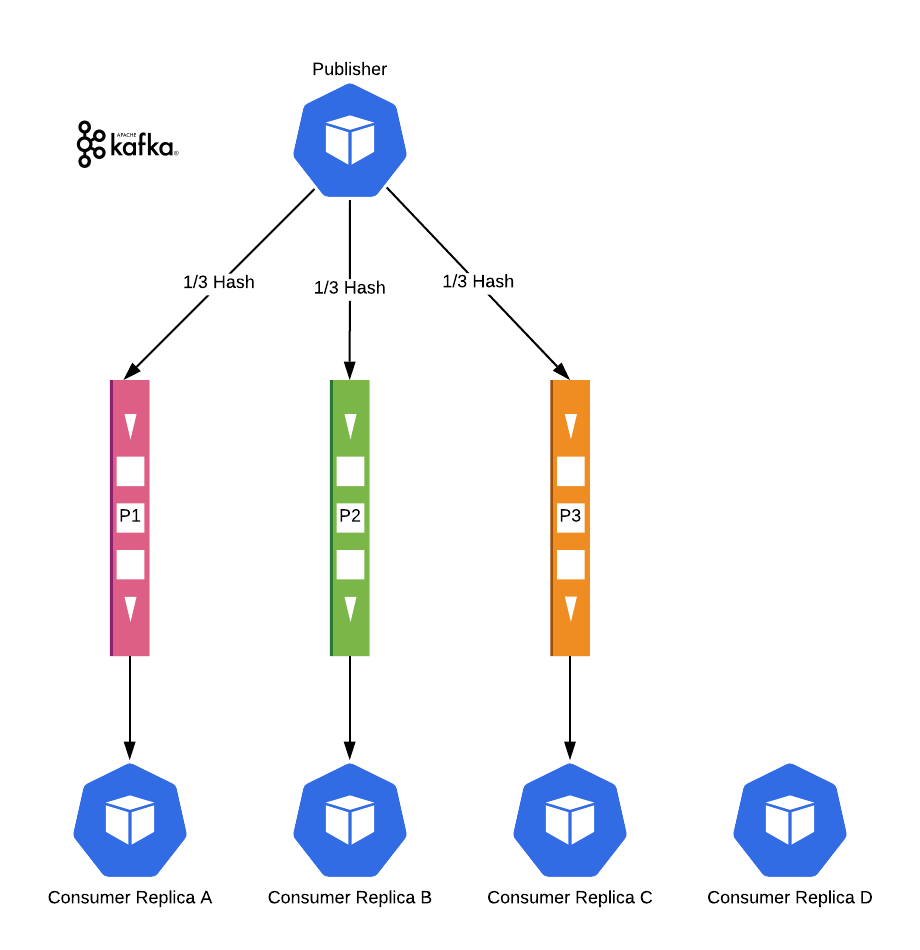
But by deciding on a high number of partitions, we can use auto-scaling and have our message ordering too. So in our case, it was a win for Kafka.
Other than this main difference, we liked a few more things with Kafka. Its log nature for one, which we relied on for our web-socket and distributed tracing solutions. Organizationally, people liked the idea of having only one copy of a message more than having it copied to different queues in RabbitMQ. Also, even if we are still not using it, the option of having an event-sourcing infrastructure was attractive.
P.S.: When we were making these decisions, Apache Pulsar was not mature yet. I think for new projects, it should be considered as a contender too.
Delayed Executions
You know, what if I don’t want to do it now situation.
Kafka does not have built-in support for future jobs. You can’t send a message to be processed x minutes from now. Yet sometimes it is what you need to do. You will need some background job handler that sends the message to the Kafka broker at the scheduled time, which then will be processed immediately. Here is how we did it.
As I mentioned earlier, we were trying to limit the third-party tools as much as possible, and we did not need advanced scheduling or CRON Job capabilities. Like many microservice applications out there, we already had Redis in our ecosystem. So we went for it.
We have a straightforward service that polls Redis for scheduled messages and passes them to the desired Kafka topic with the predetermined hash key.
We call the data structure that contains the message, destination topic, hash key, and delivery time an Envelope. Clever, right?
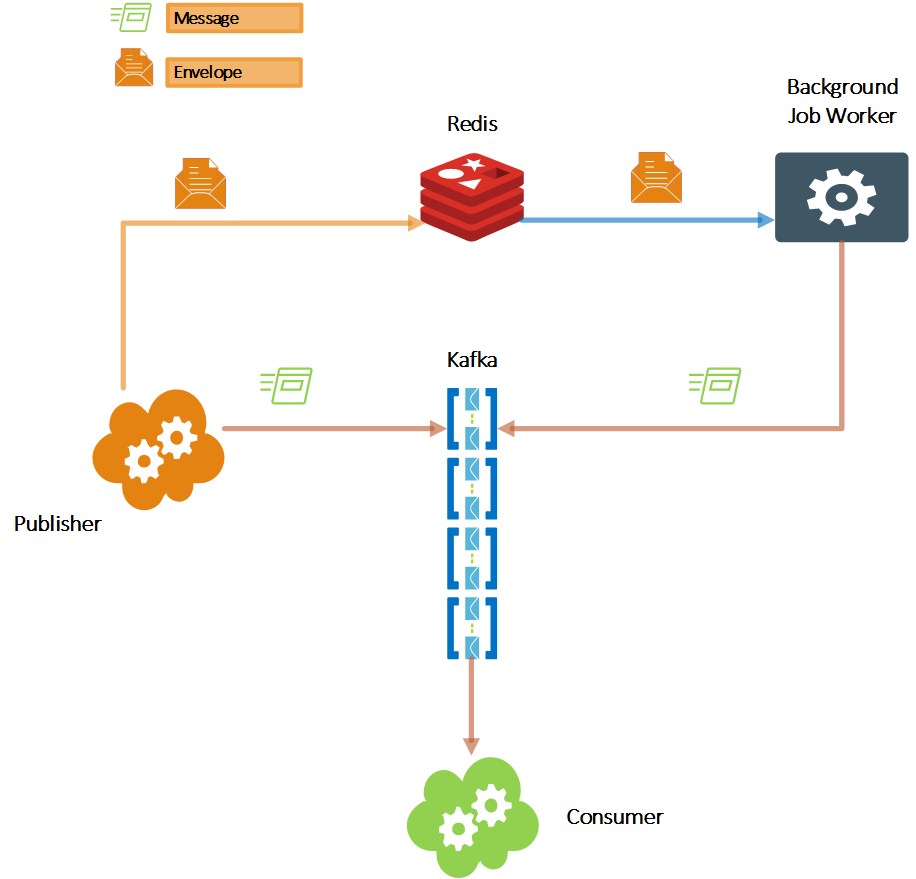
It works well enough. In any case, it is decoupled from the rest of the system, so if we need more advanced capabilities, we can easily replace it with another tool.
The critical thing to be aware of is that the Background Job Worker has the potential for being a single point of failure. Therefore it needs to be scaled too. So the first thing to consider is to use Redis transactions to prevent multiple executions of the same job by different worker instances. The second thing to consider is to not rely on it. Having multiple instances in a distributed environment is the ultimate recipe for things to go wrong. Therefore plan for idempotency. Just in case 🙂 We will talk about idempotency again.
Distributed Tracing
Oh, that age-old question; Who started the Mexican wave?
Before we continue, let me mention a couple of things. There are some capable distributed tracing tools out there with Kafka support. You should utilize them. Search: Kafka Opentracing Instrumentation. We are not trying to step on any toes here. What I will mention here is an additional, in-your-face solution that we are in complete control of, which opens up other possibilities.
What we call a Message is a wrapper class that contains the data we want to send as Payload. It has additional attributes that we use to perform other operations on our infrastructure. Kafka itself attaches some header values and attributes to the messages you send. So to prevent confusion, let’s call our class PlatformMessage. PlatformMessage is a generic class as such;

For distributed tracing, we keep a couple of extra information. The first request that starts the business process is made with a RequestId. We will visit this later. Additionally, every message has a unique-id. During the business process, whenever we need to create a new message, we use the method “CreateFollowUpMessage.” This method automatically populates the BreadCrumbs attribute. The BreadCrumbs attribute, as you may have guessed, keeps a list of ordered message metadata so that we can trace back the past events in order.
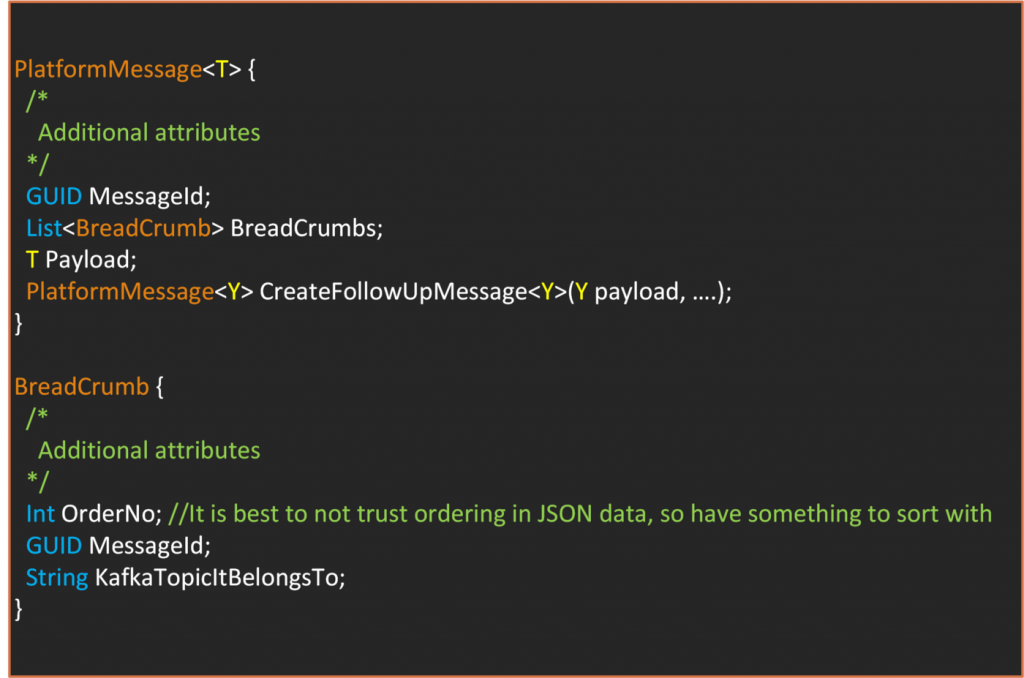
Whenever you have a message by just looking at its content, you can understand what past events resulted in its creation. It is a simple solution that helps a lot with debugging. It is visible, does not require additional tooling, and it helps solve other problems that we will cover later. But it has its shortcomings. It does not give you a complete picture of the forks, where multiple messages are produced at the same time. It does not tell you about the following messages. You can add performance metrics, but that probably be an overkill and should be better handled by a dedicated tracing solution.
So I recommend this approach as an additional feature to a third party tracing solution.




